スケジュリング問題シミュレータ「JSP-Simulation」の使用方法
○更新履歴○
2001年3月7日 Version1.10を公開。
2001年1月15日 Version1.01を公開。
2000年12月30日 Version1.00を公開。
Version1.10では、全ての子供が交叉によって生じてしまうバグを修正。
Version1.01では、交叉におけるバグを修正。処理速度が上がりました。また、
個体数、世代数の上限を増やしました。
○スケジュリング問題(JSP)について
・ある決まった数のタスクを定められた順番で処理してゆく「仕事」(以下Job)がいくつか用意されています。
・Jobに応じてタスクの順番が決まっています。またひとつのタスクにかかる時間も定義されています。
・ひとつのタスクはひとつの機械で処理されます。
・各Jobに定められたタスクの順番を守りながら、対応する機械にタスクを割り当ててゆき、いくつかのJob
を最短の時間で終わらせるように機械の稼動スケジュールを立てるのがJSPです。ひとつのJobにおける機械の
数や、Jobの数が多くなると探索空間が広くなり、最適な解を見つけるのは困難になります。
○仕様
・JSPとしてJob数50,機械数50までを扱えます。
・問題の設定は問題を記述したファイルを読みこむことで行います。
・解の探索にはGAを用います。個体数の上限は2000、世代数の上限はlong intの大きさです。遺伝的操作として、
交叉、突然変異、エリート保存を行います。
・染色体はJob番号の並びによって表現されます。Jobによって処理する機械の番号が分かっているので、
Job番号を染色体の頭から読み込んでいけば、そのJob番号の出現回数によって次に処理する機械番号
を知ることができます。読み込んだ順に、制約を満たすように機械にスケジュールを配置してゆくことで
全体のスケジュールが一意に決まります。
・適合度の値は、全Jobの完了時間にしてあります。
・親の選択にはルーレット、トーナメント、ランダムが選択できます。
・ルーレットは各個体の適合度をF(i)、最良個体のそれをF(best)とすると、
r(i)=1/{F(i)-F(Best)+10}
を計算し、r(i)の総和Rをとります。
∑i=0 r(i) < R×rand(0,1)
≦∑i=0 r(i)
なるjをルーレット値として定まった個体IDとします。
・トーナメントは決まった個体数をランダムに選び、その中から最良の適合度をもつ個体を親とします。
・交叉は2点交叉を行います。上述の染色体の表現方法では、各Job番号が決まった数(機械数)だけ
出現しなければならないので、交叉点間で同じJob番号が存在するときは、位置を保存して相手の子
に移し、あとは自分の子の染色体の空いたところに移します。
・突然変異は同一個体内で、遺伝子(=Job番号)の位置を入れ替えるようにします。
・以上の仕様は、平野廣美,「遺伝的アルゴリズムと遺伝的プログラミング」(パーソナルメディア)
に詳しい解説があります。
・結果は最も早い世代に出た最良成績の個体について表示しています。
○使用方法
ファイルの作成
・問題を記述したファイルを作成します。テキストファイルに次のように記述します。
(1)1行にひとつのJobを[]でくくって記述します。
(2)そのJobを実行するプロセスに従って「_機械番号,時間,」と記述してゆきます。
時間とは、その機械にかかる作業時間です。
(3)スペース、カンマを忘れずに。機械番号は0から入れます。
(4)行数がJob数に対応します。すべてのJobで機械数が一致していないといけません。
(5)拡張子は何でも結構ですが、.txtあるいは.datがいいでしょう。
・例を示します。
[ 1,7, 0,5, 2,3, 3,9, ]
[ 3,9, 2,6, 0,4, 1,5, ]
[ 1,3, 3,2, 2,5, 0,1, ]
これは3Job4機械問題です。1行目に記述されたJob0は、まず機械1を時間7だけかけて行い、次に機械0を、続いて機械2、
機械3の順で行います。2行目のJob1、3行目のJob2も同様です。

設定
・設定は上のタブシートで行います。"Problem data" では問題の読み込みを行います。"Read File"
のボタンを押して自分で作成したファイルを指定します。"BenchMark Problem" は、最適解が知られている
問題です。(それぞれ55、930、1165です。)これを選択すると、自動的に問題が読み込まれます。
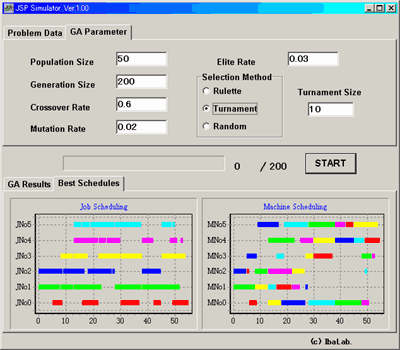
・"GA Parameter" のシートではGAのパラメタである集団個体数、世代数等の設定を行います。"Size"
には正整数を、"Rate" には(0,1) の小数を設定してください。"Selection Method" では、次世代の親を
集団から選択する方法を決めます。
実行と結果
・「START」ボタンを押すと、設定したパラメータでシミュレーションが始まります。
"GA Results" のシートには世代ごとの平均適合度、最良適合度がリアルタイムに表示されます。
・シミュレーションが終了すると、結果が記述されます。"Best Schedules" のシートには最良個体による
スケジュールがグラフで表示されます。"Job Scheduling" の色と"Machine Scheduling" の色は対応
しているので、どの処理がいつ行われているかを読み取ることができます。
・グラフ内においてマウスで右下に範囲選択をすると、その部分が拡大表示される
ようになっています。拡大を戻すには左上に向かって範囲選択をします。
・グラフ内で右クリックするとPop Up Menuが出て、グラフをクリップボードにコピーあるいはファイルに
保存することができます。(いずれもBMPフォーマット。)グラフを拡大表示すれば、
拡大表示された画像が保存できます。
UNIXバージョンについて
C言語によるシミュレータに関して簡単に説明しておきます。
○更新履歴○
2001年3月7日 Version1.10を公開
2001年2月25日 Version1.02を公開。
2001年1月15日 Version1.01を公開。
2000年12月30日 version1.00を公開。
Version1.10では、全ての子供が交叉によって生じてしまうバグを修正しました。
Version1.02では、問題ファイルの読み込みが正しく行われないバグを直しました。
○仕様
・Windows版では機能が足りない、自分独自のシステムを組みたいという人に向けて作成したものです。
・入出力はコマンドラインを介して行います。
・コア部分はWindows版とほぼ同様で、双方の環境で実験した結果を混ぜても統計的には有意です。
○使用方法
・ファイルはjsp.c/h,init.c/h,ga_loop.c/h,after_treat.c/h,makefileと問題データファイル
で構成されています。
・makeコマンドで実行ファイル"jsp"を作ります。makeが通らない場合はひとつずつコンパイルした
のちリンクして実行ファイルを作ります。
・出来上がった実行ファイルを実行します。
・コマンドラインからパラメータの入力が求められますので、適切な値を入れてください。
○コメント○
・Windows版、c版ともにバグが(結構)あると思います。皆さんのフィードバックを期待します。
・最適解を求めるのは容易ではありません。(MT6-6はあっさり見つかりますが。)現在の仕様で
パラメタを変えることで求められればいいのですが、GAの手法(選択方法や交叉方法等)に改善が必要かもしれません。
現在の仕様を理解した上で、改造できる方は独自の方法を実装してみてください。