
LGPC for image compression
LGPCによる画像圧縮をするシミュレータです
What's Image Compression?
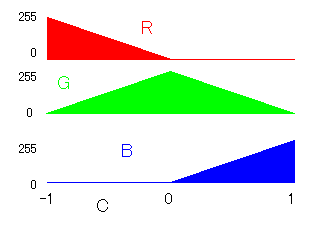
Image Copressionは、画像を表現する関数を求めます。具体的には与えられた画像に対して、x, yを座標(-1 < x < 1, -1 < y < 1)、cを色(-1 < c < 1)として、c = f(x, y)を満たすfを近似します。cとRGBの対応関係は以下の図に示す通りです。たとえば c = 0 ならば (R,G,B) = (0,255,0) です。
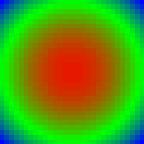
fと、それに対応する画像の一例を下に示します。
f(x,y) = x^2 + y^2 - 0.95
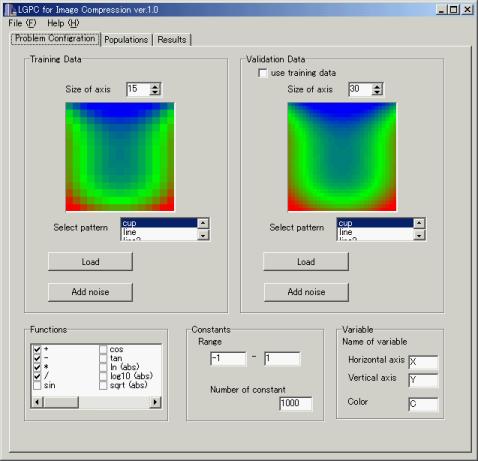
Problem Configuration
Image Copression問題の設定をします。
- Training Data
訓練データに用いる画像パターンをリストから選んでください。ファイルで与える場合はLoadを押して適当なファイルをロードしてください。ファイルのサンプルは解凍したImageCompressionフォルダに入っています。Size of axisで画像の一辺のピクセル数を設定できます。またAdd noiseで画像にノイズを加えることができます。
- Validation Data
テストデータに用いる画像パターンをリストから選んでください。得られた関数の評価に使用します。use training data をチェックすることで、訓練データをそのまま使うことも可能です。Load、Size of axis、Add noise の機能については Training Data と同様です。
- Functions
GPの非終端記号としてどういう関数を使うかを決めます。使いたい関数にチェックを入れてください。なお"if >"、"if <"はそれぞれ次のような関数です。
- if A > B C D ・・・もしA > BならばCの計算結果を、そうでなければDの計算結果を返す。
- if A < B C D ・・・もしA < BならばCの計算結果を、そうでなければDの計算結果を返す。
- Constants
GPの終端記号として使う定数値の設定です。値の範囲と刻みを入力してください。
- Variable
変数名の設定です。
Populations
GPに使うパラメータの設定です。
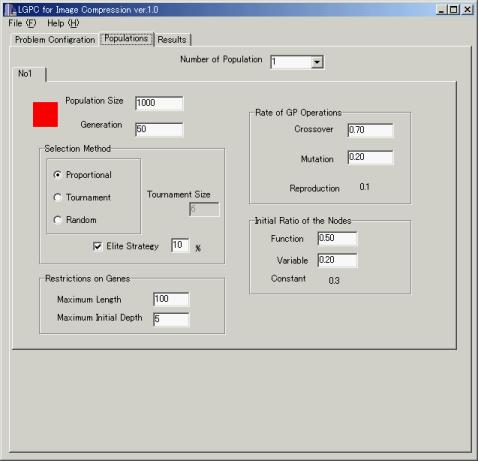
- Number of Population
集団の数を設定します。集団ごとに違うパラメータで進化させることが可能です。
- Population Size
個体数を設定します。
- Generation
何世代進化させるかを決めます。
- Selection Method
戦略を決定します。戦略にはルーレット方式(Proportional) トーナメント方式(Tournament)ランダムの3つがあり、オプションとしてエリート戦略をとるかどうかを選択することが出来ます。
- Restriction on Genes
遺伝子に許される最大長を決めます。
- Rate of GP Operations
交叉(Crossover)や突然変異(Mutation)一点交叉(One-point Crossover)の起こる確率を決めます。
- Initial Ratio of the Nodes
初期状態の各ノードに関数が入る確率と終端記号(定数・変数)が入る確率を決めます。
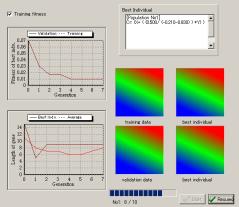
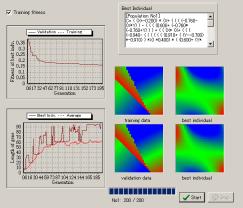
Results
結果を示します。
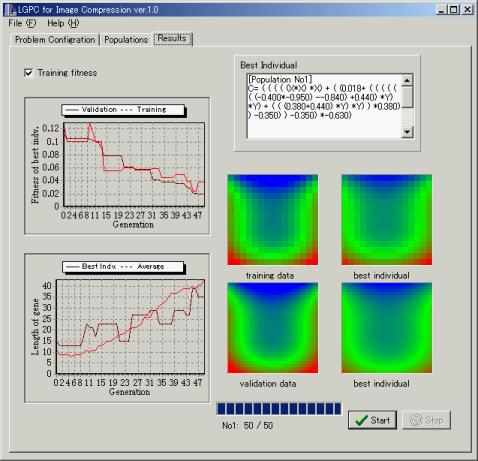
左側にはその世代で最も優秀な個体の適合度や遺伝子長、全個体の平均遺伝子長などがリアルタイムに示されます。右上は最も適合度が高い個体の遺伝子コードで、右下 はGPにより出来上がった関数で描かれる画像を訓練データ・テストデータとともに表示します。
シミュレーション例と結果
LGPC for Image compressionを用いて、様々な問題設定を行い、パラメータを変化させ探索の効率を求める実験を行いました。動作環境は以下の通りです。
OS : Windows 2000 , CPU : PentiumⅡ 400MHz , メモリ : 256MB
- 個体数及び世代数と適合度の関係
画像パターンはcircleとし、その他の問題設定はデフォルトのままとした。パラメータとして個体数及び世代数を変化させ(他のパラメータはデフォルトのまま)、シミュレーションが終了した時の適合度の値を調べた。一回のシミュレーションでは同じ環境でも適合度は変化するので、5回シミュレートした時の平均値を採用した。個体数と最も優秀な固体の適合度の関係を表したグラフを図1に示す。
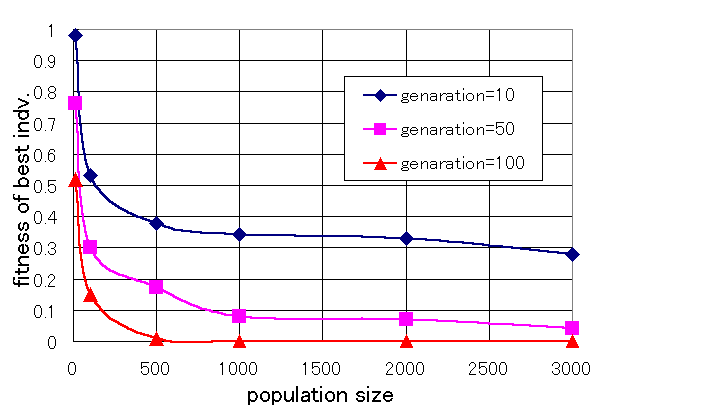 図1 個体数と最も優秀な固体の適合度の関係 |
個体数が増えるほど、適合度が高い個体が存在しやすくなることが図1から分かる。個体数が1000以下の場合は個体数の増加により、適合度は急激に高まっている。また、個体数が1000を超えると適合度は高まるものの、その傾きは穏やかになる。
また、世代数が増えるほど適合度が高くなることも分かる。したがって、優秀な個体を育てるためには個体数と世代数を増やせばよいことが図1から分かるが、それらのことは直感的にも明らかである。このシミュレータはGPで作成されているためにこの目的は、ただ優秀な個体を見つけるのではなくいかに早く優秀な個体を見つけるかであるといえる。そこで、個体数及び世代数とシミュレーションに要する計算時間の関係を求めた。その関係のグラフを図2に示す。
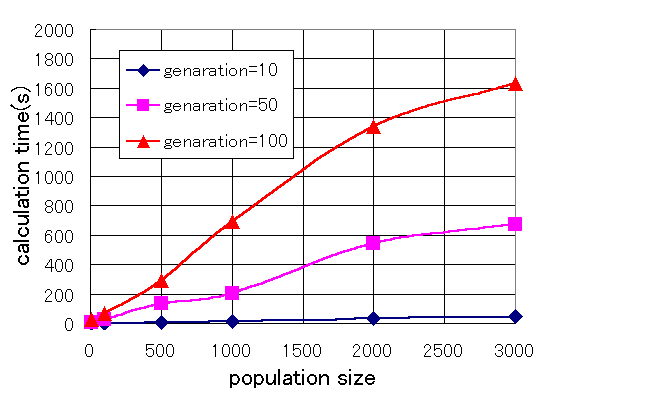 図2 個体数及び世代数とシミュレーションに要する計算時間の関係 |
図2から分かるように、個体数及び世代数に対し計算時間は線形的に増加していない。計算時間は、個体数1000あたりまではほぼ線形的に増加しその後飽和していることが分かる。また、世代数が増加すると計算時間は線形以上に増加していることが分かる。世代数の増加に伴い、一般的には遺伝子コードは長くなる傾向があるため、世代数に比例した以上の計算時間を要することになると考えられる。
適合度によって、出来上がった関数で描かれる画像と元の画像パターンがどれほど違うかという目安として各々の画像を図3に示す。当然、同じ適合度であっても遺伝子コードにより描かれる画像は異なるが、適合度が0.1以下になるとその画像は元の画像パターンに似た形となり、0.01以下になると区別をするのが困難になるほどの一致した画像パターンが生成される。
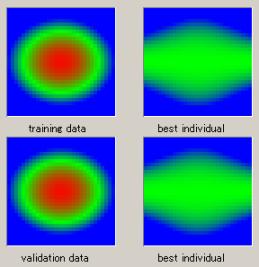 適合度:0.2 |
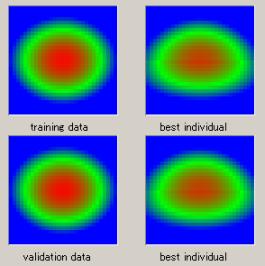 適合度:0.06 |
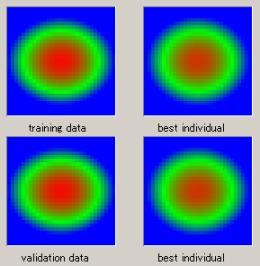 適合度:0.01 |
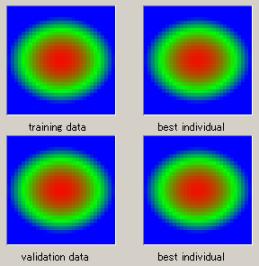 適合度:0.002 |
| 図3 適合度による画像パターンの違い | |
- 画像パターンと計算時間の関係
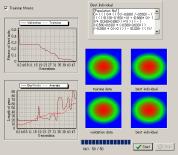
画像パターンによってはいくら時間を費やしても一致しない場合や、すぐに一致する場合があることが分かった。最も即座に一致が見られる画像はlineであり、5世代以内にはほぼ完全に一致することが分かった。連続的な画像ほど若い世代で一致しやすい傾向があることが様々なパターンでシミュレートすることにより分かった。逆にline3のような不連続な画像は世代がいくら経過しても、一致させることは難しい。用いる関数自体が連続的なものが多く不連続な関数を生成する可能性が小さいからであるといえよう。それぞれのデータの結果を図4に示す。図4のline3では、200世代経過しても全く一致する傾向が見られない。
 画像パターン:line |
 画像パターン:line |
| 図4 画像パターンによる適合度の違い | |
- 交尾率及び突然変異率と適合度の関係
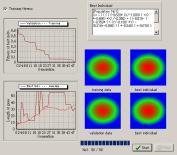
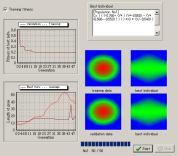
デフォルトでは、交尾率が0.7、突然変異率が0.2であった。交尾率+突然変異率=0.9として、それぞれのパラメータを変化させ適合度の値を何度も繰り返し調べた。交尾率の値による適合度の変化は小さかった。しかし、交尾が支配的な場合では適合度の非常に高い個体は発生しなかった。一般的に、突然変異がない場合では、初期の遺伝子の組み合わせ以外の空間を探索することができず、求められる解の質にも限界がでてくる。逆に、あまりに大きな変異確率に設定するとスキマタがことごとく破壊されるためにランダム・サーチと化してしまう。したがって、大きすぎもなく小さすぎもない適度な変異が望ましいといえよう。各々のパラメータによって5回シミュレートした時の最も適合度の高い結果を図5に示す。
 交尾率:0.9,変異率:0.0 |
 交尾率:0.5,変異率:0.4 |
 交尾率:0.0,変異率:0.9 |
| 図5 交尾率及び突然変異率と適合度の関係 | ||
- 戦略と適合度の関係
優れた適合度を持った個体を発生させるには、どの個体同士を交配させるかが重要である。交配の戦略として、以下のような方法が提案されている。
- 適合度比例戦略
- 期待値戦略
- ランク戦略
- エリート保存戦略
- トーナメント選択戦略
- ランダム戦略
このプログラムでは、適合度比例戦略、エリート保存戦略、トーナメント選択戦略、ランダム戦略の中から選択することができる。それぞれの戦略の内容は以下の通りである。
- 適合度比例戦略
ルーレットモデル、モンテカルロモデルとも呼ばれ各個体の適合度に比例した確率で子孫を残せる可能性があるモデルである。選択確率の大きな個体ほど複数回の交配に参加できるので、その遺伝子は集団中に広がっていく。 - エリート保存戦略
集団中で適合度の高い個体をそのまま次世代に残す方法である。この方法を採用すると、その時点で最も良い解がクロスオーバーや突然変異で破壊されないという利点がある。ただし、あまりに適合度の高い個体を多く次世代に残すとエリート個体の遺伝子が集団中に急速に広がる可能性が高いため局所解に陥る危険もある。一般にこの戦略は、他の選択戦略との組み合わせで使われる。 - トーナメント選択戦略 集団から決められた数の個体を無作為に選択し、その中で最も適合度の高い個体を次の世代に残すという手続きを次の世代に残したい数の個体が選択されるまで繰り返すという方法である。
- ランダム戦略
ランダムに選択された個体を次世代に残していく方法である。
エリートを保存する割合を変数として、それぞれの戦略による最も高い適合度をシミュレーションにより求めた。環境はデフォルトの通りとした。また、この場合も同様な環境でのシミュレーションであっても、最も優秀な個体の適合度は異なるので、5回シミュレートしその平均値を最も高い適合度の値とした。このようなシミュレーションにより得られた戦略と適合度の関係を図6に示す。
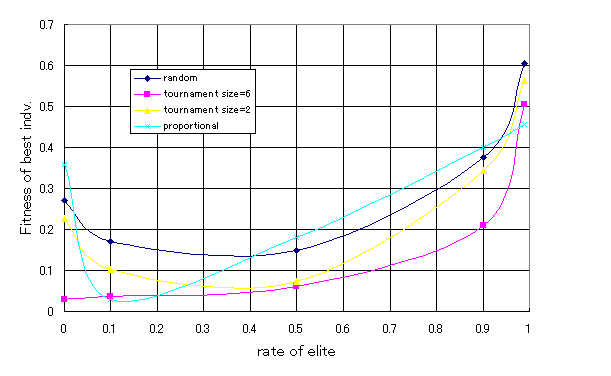 図6 戦略と適合度の関係 |
図6からも分かるように、エリート保存を行う割合により、適合度は大きく変化することが分かる。特に、エリート保存を行う割合が十分大きくなると適合度の高い個体が生まれにくくなってしまうことが分かった。逆に、エリート保存を行わない場合では、せっかくの優秀な個体が失われる状態が発生し全体的に、適合度の高い個体は存在しづらくなってしまう。また、ランダム戦略は他の戦略と比べ有効な戦略ではないと言える。
結局、優秀な個体はある程度残しつつ優秀でない個体は、突然変異や交配をさせたりして、他の解を探させるのが有効であることが分かった。