
レポート課題:人工知能
講義のホームページはこちらです.
締め切り
第一回レポート(第1問~第6問):12月22日の23:59まで。
注意事項
- 講義の内容により変更の可能性がある。最終的な内容は必ず講義の際に確認すること。
- 各回で提出する課題数は任意であるが、最低数は1問である。 問題の難易度を印で示しているので、提出の際の参考にすること。 簡単な問題であれば2問以上を提出することがのぞましい。
- 原則として、締切日より遅れて提出された場合は 採点の対象としない。 ただし、何らかの理由があれば、 締め切りまでに提出したレポートについて更新・修正版をのちに 提出することは認めることがある。
- また、特段の理由があれば提出期限を延長する。
レポート採点方針
- 当然ながら提出したからといって満点とは限らない。
- とりあえず適当に書いて提出するというのは印象が悪いので注意せよ。
- 最終評価は合計点をもとにした相対評価となる。
- 難しい問題に挑戦したり、多くの人が解かないような問題を解答すると ポイントが高い。
- AIらしいユニークな解答も評価する。
- 参考までに★で難易度を示しておく。
課題内容
- (第1問:課題番号01★)
昨年度のノーベル化学賞はゲームAIに関連している。
その詳細はこのHPなどに詳しい。
では、Folditを遊んでみてその実体験を報告せよ。 ただし 個人の責任でゲームに参加すること。
とくに、
- ゲームに直観が有効だったか
- 本格的な科学に貢献できる意識があったか
- 共同作業・闘争意識の効果はあるか
- ShakeやWiggleなどのツールは局所解の脱出に役立ったか
- チュートリアルを含めてどのくらいの時間で何位まで達成したか
- 将来のAIの応用に貢献するか
また、ある程度の順位(過去で受講した者の最高記録:7000+,10位)は必須である。「ちょっとやってみた」というようなレポートは評価が低い。
Hint1: Foldit!の解説は 教科書 の6.1節にある。
Hint2: 説明のスライドはここにある。また、Foldit!をもとにしてNatureに掲載された論文はここにある。
- (第2問:課題番号02★) 講義で説明したように、 三段論法推論にはヒトにとって解き易いものと解き難いものがある。これについては、 メンタルモデル( 教科書1.3節)による説明が認知科学的になされている。
- 三段論法推論には教科書 の図1.7で説明しているように全部で64種類ある。これらの問題をいろいろな用語や何気ない会話で試してみる。
- LLMがいかに間違えるのか・正しく答えるのかを観察し、集計する。
- さまざまなChain of Thoughtや呪文を工夫してみよ。
- どのように錯覚して回答するのかを記述する。
- (第3問:課題番号03★)次の2問にすべて答えること。
- 進化計算の原理を身近な例を用いて分かりやすく説明せよ。少なくとも以 下の項目についてアナロジーで解説すること。
- 交叉
- 突然変異
- 世代交代
- 集団初期化
- 選択・淘汰
- 適合度計算
- 探索が上手くいくようす
- 進化計算の面白い応用例・実用例について調べて考察せよ。 講義などで説明した例や以下のような著名な例は除く。
- 遺伝的アルゴリズムでブランコの漕ぎ方を学習させた動画
- 進化するマリオのお話
- 対話型似顔絵作成システムNIGAO
- グラディウスを学習させてみた
- GAでモナリザを描く
- Mondriaan Art by Evolution on the Web
- 遺伝的アルゴリズムを用いてハイハイを学習させる
- 畝見先生のSBART(抽象画生成)
- Synplant「遺伝を利用したソフトウェアシンセサイザ」
- 『グリムノーツRepage』から見る遺伝的アルゴリズムのゲームバランス調整における事例とその可視化
- 進化計算をオープンハウスの宅地自動区割りに活用
- 物流センター在庫配置最適化
- 三菱電機のZEB(net Zero Energy Building)における設備運用最適化およびアスクルの在庫配置最適化の事例
- 放送局CM順位づけ業務に「進化計算ダーウィン」を導入
- 対話型進化計算を利用したネックレスデザインシステム
- sakanaAIの進化的アルゴリズムによる基盤モデルの構築
- (第4問:課題番号04★★) 次のようなスタンプパズルを考えよう。盤の上に〇かXの印が置かれている。スタンプを押すと〇とXが入れ替わる。 ただしスタンプは回転して使うことができるが、枠の外にはみ出して一部だけ押すことは許されない。
- (第5問:課題番号05★★★) ノーベル化学賞はタンパク質のフォールディング問題の解法によるものであった。これに関連してHPモデル格子型構造予測問題をGAで解いてみよう。
- 標準的なGA(ダーウィン進化)
- ボールドウィン進化 型GA:個体の適合度を評価するため、その個体をスタート地点としてとり、局所解に達するまで山登り法などで局所探索を実施する。もとの個体の適合度は上で得られた局所最適解である。しかし子孫を作るときには、局所探索による「学習済み」の改善個体ではなく、オリジナルの個体の遺伝子型が用いられる。
- ラマルク進化型GA:ボールドウィン進化と同じく、局所探索を行い適合度を評価する。 ただし、局所探索で改良された個体によって子孫が作られる。つまり獲得形質を受け継ぐ。
- 配列20 (HP)2PH2PHP2HPH2P2HPH
- 配列48 P2HP2H2P2H2P5H10P6H2P2H2P2HP2H5
- 配列48 HPH2P2H4PH3P2H2P2HPH2PHPH2P2H2P3HP8H2
- 配列48 PHPH2P2HPH3P2H2PH2P3H5P2HPH2(PH)2P4HP2(HP)2
- 配列48 PH2P6H2P3H3PHP2HPH2(P2H)2P2H2P2H7P2H2
- (第6問:課題番号06★★★) 平面上に23個の点をできるだけ「美しく」配置せよ。
- 例えば、10個の点であれば以下のようなものが考えられる。
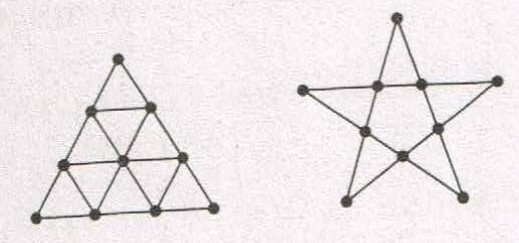
- 進化計算を推奨するが、ニューラルネット、強化学習、その他のAI手法で探索してもよい。
- 評価関数(「美しさ」の基準、適合度)を工夫すること。例えば、対称性の個数、直線状に並んだ数、思いつきにくさ、希少性、力学的エネルギ―最小化などが考えられる。
- 個性を生かすことが重要なので、他の点数でも配置可能なもの(円周上、直線上など)はポイントが低い。
- 他の個数の点でも同じ基準ではできるだけ面白くなってはいけない。
- 得られた結果がどのように面白いかを考察したかも重視する。
- 必ずしも最適解(?)が得られなくても成績評価には関係しない。 どれだけ工夫したか、考察したかで評価する。
- AI探索が目的なので、LLMに聞いたというような解答は原則的に認められない。
- プログラムを作成した場合、 実現したシステムに関する説明(どの部分をどう創意工夫したかなど)。さら にアルゴリズム、ソースリストの説明。
- 結果の表示(グラフなどを用いると分かりやすい)。
- 結果に関する考察と評価。
- 授業に関するコメント、要望など(次回の参考にするので是非書いて下さい)。
(1) LLM(大規模言語モデル)でも三段論法が解けるらしい。実際に解かせてみよ。以下の点に留意すること。
(3) また今後「強いAI」を実現するために、どのようなデータを集めて研究すべきか、論理的推論の必要性などについて論述せよ。参照した文献、引用文献、出典は必ず文献リストに挙げること。
Hint1: 参考書 の『4.4節:三段論法推論:ソクラテスは死ぬか?』では三段論法のメンタルモデルの詳細が説明されている。
Hint2: LLMによる三段論法推論の研究は ここ などにある。
なおこの課題で求めているのはわかりやすいデモや応用であり、 学術論文や技術的詳細ではない。
実応用例については、 特許・新聞記事・論文などの出典とともに、どのように応用されているかをわかりやすく平易な言葉で説明すること。
例えば、2x2の4角形のスタンプを押すことで次のように印が変わる。
|
|
|
|
|
(1)次の初期配置について、L型のスタンプを押してすべての印を〇にする手順を探索せよ。A*,深さ優先,広さ優先探索をそれぞれ実行して探索の効率(解に到達するまでのノー ドの展開数)を比較すること。ただしスタンプは回転して使っても良い。自分でA*用の効果的なヒューリスティックスを考えて実験してみるとポイントが高い。
|
|
|
|
|
(2)次のそれぞれのスタンプを使って、(1)の問題の初期状態のいくつかを解け。ただしスタンプは回転して使っても良い。 A*,深さ優先,広さ優先探索をそれぞれ実行して探索の効率(解に到達するまでのノー ドの展開数)を比較すること。自分でA*用の効果的なヒューリスティックスを考えて実験してみるとポイントが高い。
|
|
|
講義で説明した以下のプログラムを拡張するとよい。
Hint1: このパズルは解ける問題と解けない問題がある。なぜか、考えてみよう。それを考えて例題やスタンプを選ぶこと。
Hint2: 講義で説明した15パズルによる奇偶性。
Hint3: 対称性を考えて探索を効率的に行うこと。
このとき、その問題に関して次の3つの異なったGAの性能を比較しなさい。
Hint1: ボールドウィン進化とラマルク進化の詳細は 参考書 の5.1節にある。
Hint2: (2次元での)配列の例としては以下の問題に挑戦するか、任意の配列を入力としてもよい。
Hint3: GAを用いたHP folding問題の解法についての古典的論文は ここ にある。これに基づいたpython版のGAシミュレータは ここ にある。
23という数の個性をどのように生かして探索したのかについて説明すること。
見やすくなるために必要なら補助線(曲線)を書き加えよ。
Hint: たとえば対話側進化計算(IEC)で配置を進化させる試みがある。これを拡張しても良い。 IECによる23点配置の進化のunityでのデモプログラムはここにある。
提出方法
以下のものを提出すること。提出方法はここに示す通りである。